


Data archiving and retention in PostgreSQL. Best practices for large datasets
Just over a week ago, I attended PGConf.DE 2025 in Berlin with the rest of the Data Egret team and gave a talk titled “Data Archiving and Retention in PostgreSQL: Best Practices for Large Datasets.” This post is a written version of my talk for those who couldn’t attend.
Below, you’ll find each slide from the talk — along with what was said.

I’ve started talking about something that happens with almost every Postgres database — the slow, steady growth of data. Whether it’s logs, events, or transactions — old rows pile up, performance suffers, and managing it all becomes tricky. My talk was focusing on practical ways to archive, retain, and clean up data in PostgreSQL, without breaking queries or causing downtime.

As you can see my work with Postgres focuses a lot on monitoring, performance and automation. I do that at Data Egret, where we help teams run Postgres reliably, both on-prem and in the cloud.

We specialise entirely in Postgres and involved a lot in the community. We help companies with scaling, migrations, audits, and performance tuning — everything around making Postgres run better.

I was also excited to share that Data Egret is now а part of a new initiative in the Postgres ecosystem: The Open Alliance for PostgreSQL Education. It’s an effort to build open, independent, community-driven certification.
Then I dived into the topic of my talk.

Postgres can handle big tables, but once data starts piling up, it doesn’t always degrade gracefully:
- queries slow down,
- VACUUM takes longer,
- indexes grow,
- backups get heavier.
>And often, you’re keeping old data around for reporting, audits, or just in case. And that’s OKAY. Because the issue isn’t really volume — it’s how we manage it.

This isn’t about discarding data — it’s about managing it wisely. Frequently used, or ‘hot’ data, should remain readily accessible and fast to query, without being archived or moved to storage.
And cold data? Move, compress or archive it, but still keep it accessible. That’s why we’ll focus on three core strategies:
- Partitioning — to break big tables into pieces.
- Compression — to shrink storage for large columns.
- Archiving — to move old data elsewhere without losing access.
And of course, some automation, because this isn’t something you want to do by hand forever. First step: let’s look at partitioning.

It has been in Postgres for a long time, but declarative partitioning — introduced in version 10 and much improved in 11 — is the go-to approach now. Partitioning can really simplify life with large tables.
First, it makes queries faster — especially when you’re looking at recent or time-based data. Postgres can skip over partitions that don’t match, which saves a lot of work.
Second, cleanup becomes easier. Instead of deleting millions of old rows, which is slow and leaves behind bloat, we just drop the whole partition. It’s instant, and no vacuuming needed.
And speaking of vacuum. Partitioning naturally reduces bloat and spreads out autovacuum work, so performance is more stable, and big tables stay healthier over time.
In short: better query performance, easier cleanup, and less bloat. All with one strategy.

There’re a few types of partitioning. The most common is range partitioning, which works great for time-based data like logs or events. When you want to split by categories, like regions, you’ll find useful list partitioning. Also there is hash-based — it spreads rows evenly by hashing the key. Useful when you can’t split by time or category — but it’s rare in practice.
That said, partitioning isn’t always the right tool. If your table is small or most queries touch all rows, it can actually add overhead.
But when it fits, it makes cleanup and archiving way easier — and it sets you up for efficient retention.

Let’s say you already have a huge table in production and now you want to partition it. The challenge is: how do you migrate safely, with minimal downtime, and without losing data?
Well, the general flow is:
- Create a empty partitioned copy. Make sure that partition key is included in primary key.
- Set up a trigger — this keeps new operations synced between the old table and the new one.
- Backfill — in batches — so you don’t overload disk or locks.
- Create indexes — either beforehand, or after moving the data. Usually it’s done after backfill and before the switchover. We’ll talk about indexes next, by the way.
- Switchover — rename the old table, and promote the partitioned one.

When working with partitioned tables, it’s important to understand how indexing works, because it’s not like regular tables. If you run CREATE INDEX on the parent table, Postgres will: automatically create the same index on all existing partitions, and apply the same index to future partitions too. That’s convenient, but there’s a catch.
You can’t use CONCURRENTLY when creating an index on the parent. Without it, PostgreSQL takes an AccessExclusive lock on each partition while building the index. That means:
- all writes (INSERT, UPDATE, DELETE) are blocked,
- even some reads can get indirectly blocked if they wait behind those writers.
A better option in production:
- Use CREATE INDEX ON ONLY — this skips the auto-apply.
- Then create each index concurrently on the partitions.
- And finally use ALTER INDEX … ATTACH PARTITION to connect them.
This gives you control, avoids locks, and works great during live migrations.
Once you’ve indexed what you need, time went by and your partitions are no longer changing — compression is the next step.

Postgres uses a mechanism called TOAST to store and compress large values, like text, jsonb, or bytea. When a value gets too large, usually over 2 KB, Postgres moves it aside and compresses it automatically.
Since version 14, you can choose the compression method per column. The default is pglz, but you can now use lz4, which is faster and often gives better compression. Though, it depends on your data – the more duplicates you have the better will be the result of compression.
You can set this:
- at table creation,
- using ALTER TABLE,
- globally via the default_toast_compression setting.
Before recommending any compression strategy, I wanted to actually test it.
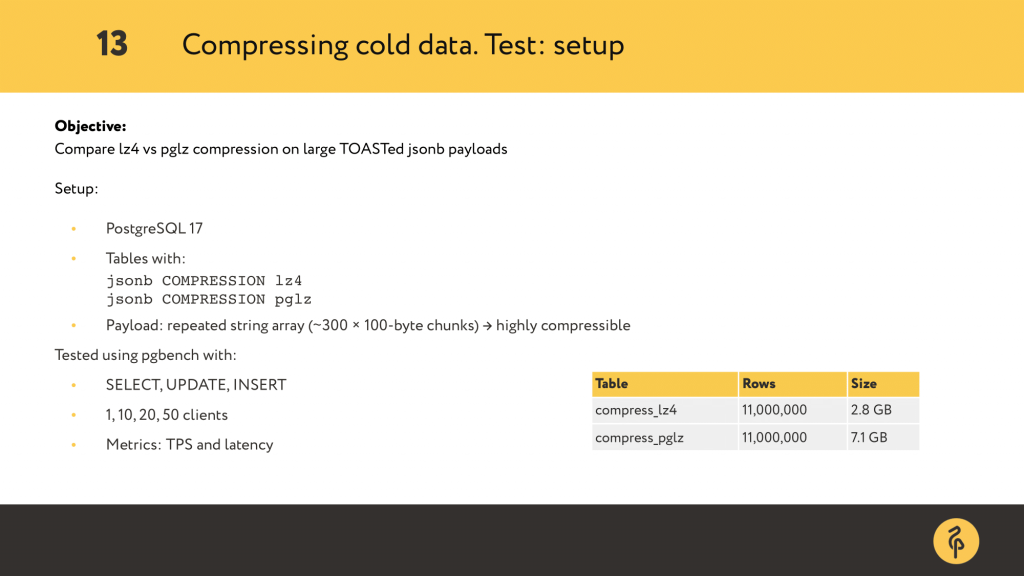
So the goal here was simple: compare lz4 and pglz for compressing large JSONB values. I used PostgreSQL 17 and created two identical tables: one using COMPRESSION lz4, and the other with pglz, the default. The data was designed to be highly compressible, basically a big JSON array of repeated chunks and about 10% of unique data to make it seem more realistic.
After I added about 11 million rows to each table lz4 ended up around 2.8 GB and pglz over 7 GB. So yeah — LZ4 was way smaller.
After that, I used pgbench with different number of concurrent clients, running SELECTs, INSERTs, and UPDATEs. Let’s take a look at what happened.
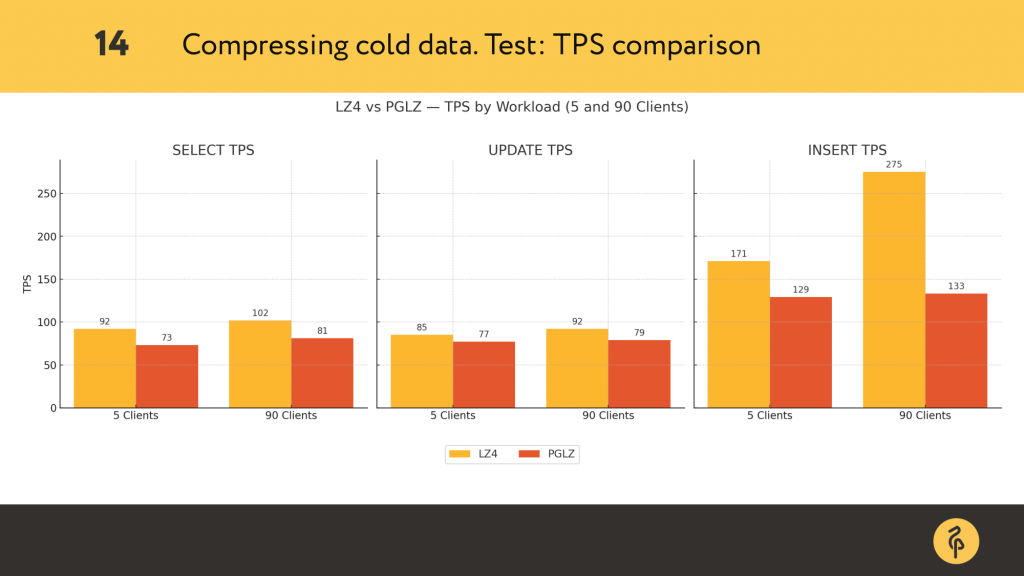
Select queries performed slightly better with lz4, especially under load, but in other tests I’ve done and seen results for select weren’t stable. Update performance was also better with lz4. And lz4 consistently outperformed pglz on inserts — almost double the TPS under high concurrency.
So we not only save disk space, but also gain significant write performance improvements. That said, compression is a nice optimisation, not a requirement.
Whether or not we compress, at some point we’ll want to offload old partitions.

We have a few options: we can export it, using COPY for CSV, or pg_dump for a compressed backup. Then we can either detach it, which removes it from the main table, or drop it completely if it’s no longer needed. Starting in PostgreSQL 14, you can even run DETACH PARTITION CONCURRENTLY, which avoids locking the parent table. This two-step process — export, then detach or drop — gives us safe and clean retention control.
And if you just detached it and not ready to delete just yet, you can always move it to cheaper storage.
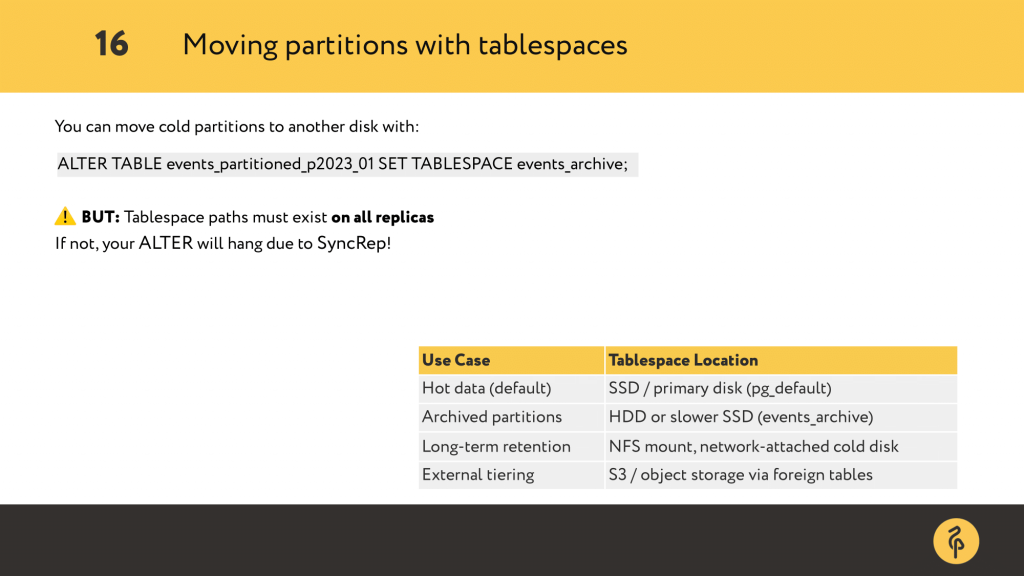
We can move it to a different tablespace which point to a separate disk, maybe cheaper or slower, just to free up our main storage. It’s easy to do with a single SQL command: ALTER TABLE … SET TABLESPACE.
Below you can see a list of common setups. SSD for hot data, HDD or NFS for archives, or even S3 for future external tiering.
Overall, tablespaces are great when you still want the data local. However, if you definitely don’t want it in your main database anymore…

Postgres gives us a flexible option through foreign data wrappers. With them we can offload tables to external files or systems, and still query it. file_fdw is the simplest. It lets you read CSV or TSV files directly from disk. Perfect for static exports like logs or monthly reports.
But there are other wrappers too — for Postgres, MySQL, S3, even BigQuery. These let you offload partitions while still being able to join or filter them with SQL.
Just keep in mind: you lose some performance and indexing, so these are best for rare lookups, not frequent queries.

One great option is parquet_fdw — it uses a columnar format popular in analytics It lets you connect these Parquet files directly into Postgres as foreign tables. That means we can move cold partitions to a .parquet file and still run SQL on it without keeping the data in the database. This works really well for archived logs, or metrics — data you don’t need often, but still want access to when needed.
So archiving doesn’t have to mean “gone forever”. It can mean “moved to slower, cheaper, but still queryable storage”.
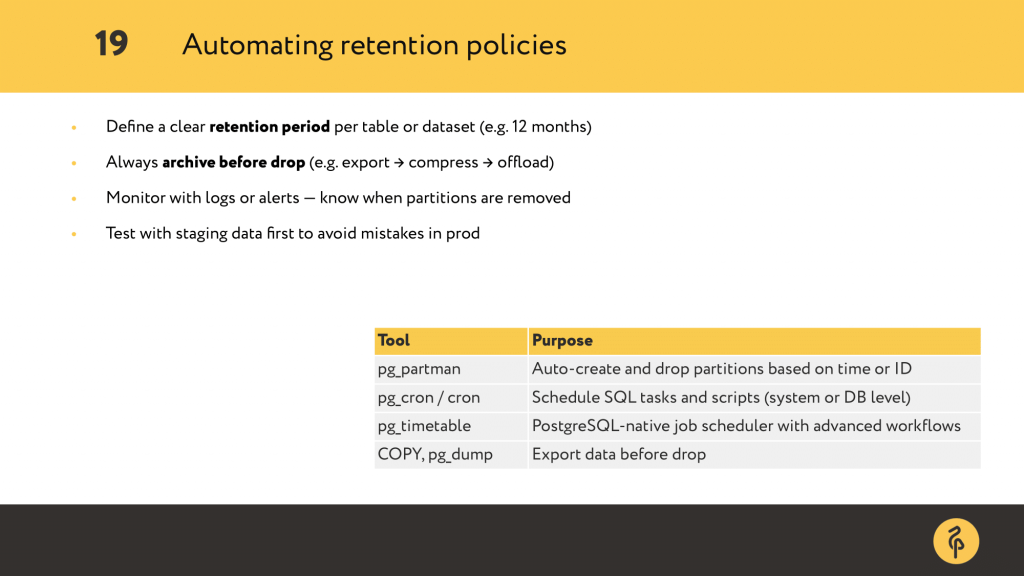
So far, we’ve looked at ways to compress, move, and clean up cold data — but doing this manually doesn’t scale. That’s where automation comes in. You’ll want to define a clear retention period for each dataset — maybe 12 months, maybe 3 — depending on your business needs. Then make sure you archive before dropping: export it, compress it.
You can automate it with tools like pg_partman for partition creation and rotation. And to schedule cleanup jobs you can use extensions like pg_cron or pg_timetable or use a small job runner to script the process.
And of course, monitor it. Add logs or alerts so you’re not surprised when a partition disappears. The goal here is: define the lifecycle once and let the system do the rest.

Here’s what it may look like in practice.
We schedule a procedure with pg_cron to run every night. It checks for old partitions, detaches them, exports to CSV, and drops them.

This is the full procedure. It loops through all monthly partitions and filters out the ones older than 12 months.
For each old partition, it does three things:
- Detaches it from the parent table using ALTER TABLE … DETACH PARTITION. Notice, that we don’t use concurrently here: it can’t be run inside a transaction block.
- Exports the partition to a .csv file, using the real table name as the filename.
- Drops the table to free up space in the database.
So, That is how you can quietly remove cold data that’s no longer needed.
But what if you’re not running Postgres on your own hardware? In the cloud, things change. Some tools work differently, and others aren’t available at all.

But the core strategy doesn’t change. Only some of the tools do.
- For example, COPY TO may not be available, but you can use pg_dump, compress the output, and upload it to S3.
- Tablespaces usually aren’t an option, so cold data often has to be moved out of Postgres entirely — to S3, external databases, or long-term storage.
- Cleanup logic that we ran with pg_cron on-prem can still run in RDS and AlloyDB. And if it can’t, you can schedule it with Lambda, Cloud Functions, or other external job runners.
The key takeaway is that you still can — and should — manage data lifecycle in the cloud. You just need to rethink where the data lives, and how you automate its movement.
Whether you’re on-premises or in the cloud — once you start implementing these techniques, there are some things to watch out for…
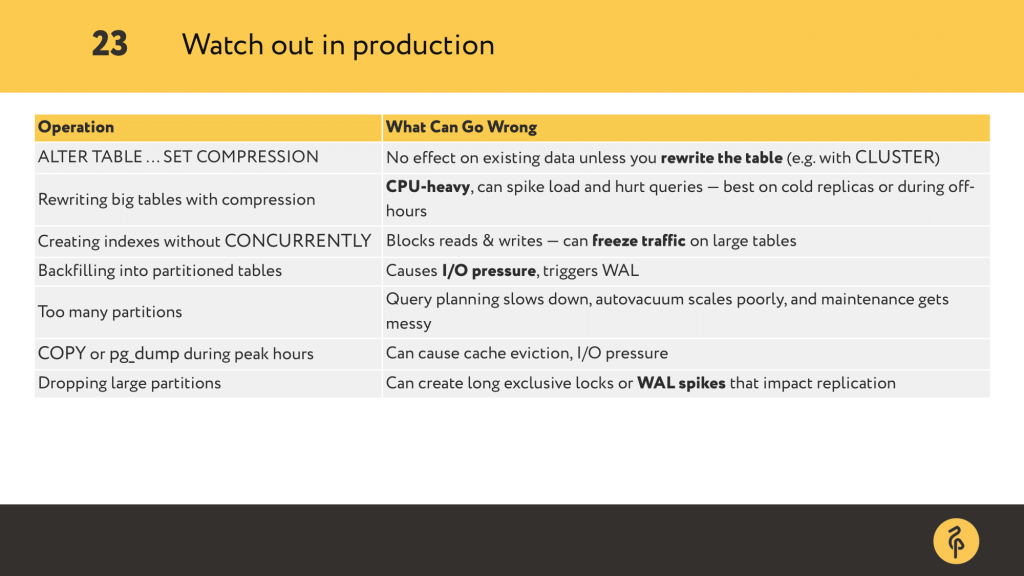
Let’s start with compression: if you set it on existing table nothing happens to the existing rows unless you rewrite the table.
That could mean CLUSTER, or even a bulk UPDATE. But keep in mind — rewrites like that are CPU-heavy, and they can really spike load, so it’s best to do them after-hours.
Creating indexes can also be risky. If you forget CONCURRENTLY, Postgres will lock the table for reads and writes. That’s enough to freeze traffic in production.
Backfilling into partitions — especially older ones — may sound harmless. But it causes I/O pressure and generates WAL files. Speaking of partitions: too many of them could slow down query planning and make autovacuum less efficient.
Even things like COPY or pg_dump seem safe — but if you run them during busy hours, they can increase reads and hurt query performance.
Dropping a large partition? That can trigger exclusive locks and generate a WAL storm that delays replicas.
So yes. Postgres gives us a lot of power. But with that power comes complexity, and sometimes risk. That’s why testing, observability, and thoughtful rollout matter.
Now, to bring it all together…

We’ve seen that Postgres isn’t just a place to store data — it gives us tools to manage it as it grows, ages, and changes.
You don’t have to wait until queries slow down or backups take hours. Partitioning gives you structure, compression gives you breathing room, and archiving clears the path forward. But none of it works without automation. And none of it works without intention.
So no matter what kind of data you manage — logs, events, user history — the real win is staying intentional — about what you keep, how long you keep it, and where it lives.
Have questions or comments? Post them below, I’d love to hear your feedback!



