

PostgreSQL Performance Meltdown?
Overview
On the 30th of December 2017, Kernel page-table isolation (PTI) patch had been merged
with the mainline. Its main goal was to mitigate the Meltdown bug.
This patch has also been backpatched into the stable releases by RedHat, Debian, CentOS, Ubuntu and other Linux vendors. Therefore, the nearest security upgrade of the servers running on such stable releases will get PTI feature.
Unfortunately, this bugfix comes with the performance penalty.
Andres Freund provided figures, showing that performance might drop by 7-23% on TPC-H alike workloads.
Meltdown vulnerability “allows a rogue process to read any kernel memory, even when it is not authorized to do so”. PTI is designed to close this flaw, i.e. restrict memory access to the unauthorized areas. Of course, this comes at a price and it’d be good to find out what performance impact it will have after Linux kernel upgrade. As PTI affects memory-based operations, one way to achieve this is to use database that fits into the RAM of the server and to perform a series of pgbench-based RO tests.
Test setup
CPU: Intel(R) Xeon(R) CPU E5-2430 0 @ 2.20GHz
RAM: 32GB (swap 16GB)
Disks: Dell PERC H710, 120GB EDGE E3 SSD in RAID1 (110GB available)
Linux: CentOS 7.3.1611
PostgreSQL: 10.1
PostgreSQL configuration changes:
bgwriter_delay = 10ms bgwriter_lru_maxpages = 1000 bgwriter_lru_multiplier = 10.0 checkpoint_timeout = 1h max_wal_size = 8GB min_wal_size = 2GB checkpoint_completion_target = 0.9 log_destination = stderr logging_collector = on log_directory = /var/log/postgresql log_filename = postgresql-%a.log log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 0 log_checkpoints = on log_line_prefix = ‘%m %p %u@%d from %h [vxid:%v txid:%x] [%i] ’ log_lock_waits = on log_temp_files = 0
Test details
Test database has been prepared with: pgbench -i -s 1700 pgbench
Database size: 26 035 MB
The following kernels and options had been tested
- Old kernel version: 3.10.0-514.el7.x86_64
- New kernel version, as-is: 3.10.0-693.11.6.el7.x86_64-pti-pcid
- New kernel, with nopcid: 3.10.0-693.11.6.el7.x86_64-pti-nopcid
- New kernel, with nopti: 3.10.0-693.11.6.el7.x86_64-nopti-pcid
- New kernel, with nopti nopcid: 3.10.0-693.11.6.el7.x86_64-nopti-nopcid
For each of the 5 “kernels”, 3 variants of shared buffers have been observed: 1GB, 8GB and 28GB.
After each restart of the cluster, tables and indexes have been pre-warmed via `pg_prewarm` module. Then, 15-minute long read-only pgbench run has been conducted.
Script of the test:
echo “shared_buffers=${SB}” > /var/lib/pgsql/10/data/postgresql.auto.conf
pg_ctl -D ~/10/data -m fast restart
echo “SELECT format(‘SELECT %L, pg_prewarm(%L);’, relname, relname) FROM pg_class c JOIN pg_namespace n ON n.oid=c.relnamespace AND n.nspname=’public’ WHERE relkind IN (‘r’,’i’)gexec” |psql -qAtX pgbench
pgbench -T 900 -j4 -M prepared -c 12 -Sr pgbench
Results
Alias | TPS (1GB) | TPS (8GB) | TPS (28GB) |
old | 92995 | 80554 | 107144 |
pti pcid | 88394 (-4.9%) | 77586 (-3.7%) | 102839 (-4.0%) |
pti nopcid | 83216 (-10.5%) | 74947 (-7.0%) | 98653 (-7.9%) |
nopti pcid | 90772 (-2.4%) | 79120 (-1.8%) | 105726 (-1.3%) |
nopti nopcid | 91387 (-1.7%) | 78856 (-2.1%) | 105593 (-1.4%) |
Test shows, that new PTI-enabled kernel brings ~4-5% slowdown for in-memory read-only operations. Using new kernel parameters nopti and nopcid (together) it is possible to disable new functionality, however, small performance reduction is still observed.
There are no general directions on whether to disable PTI, after all, its goal is to close HW-based bug. In cases, when server is dedicated to the database alone and it is a physical machine (not VM or container), it seems fine to use nopti parameter and get a better performance.
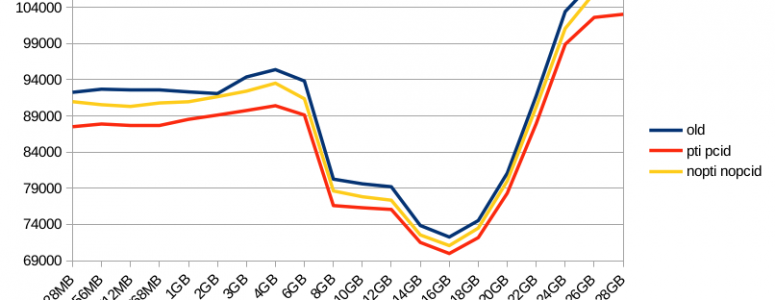
Here’s a graph, that shows TPS for the old kernel, new (PTI-enabled) one and new kernel with PTI and PCID features disabled:
There are no general directions on whether to disable PTI, after all, its goal is to close HW-based bug. In cases, when server is dedicated to the database alone and it is a physical machine (not VM or container), it seems fine to use nopti parameter and get a better performance.
Here’s a graph, that shows TPS for the old kernel, new (PTI-enabled) one and new kernel with PTI and PCID features disabled:

For the chosen test case performance penalty is not huge. And one can clearly see, why using 50% of RAM for shared buffers is not recommended 😉
Also, since larger shared buffers yield more TPS and can significantly reduce IO volume (due to only checkpoints are writing dirty blocks) it seems beneficial to use 70-80% of RAM for this purpose. This requires more tuning on the kernel level, though — HugePages are a must for such setups.



