Everything you always wanted to know about Postgres stats
This post is about pg_stat_bgwriter view. In my experience, this view is not used very often, however, I think we should take a closer look and understand where is it might become handy.
Official documentation has a very brief description that defines pg_stat_bgwriter as “statistics about the background writer process’ activity”. Quite brief, isn’t it? In this post I consider pg_stat_bgwriter in details, also take a look on the server’ background writer and checkpointer. In short, postgres has two additional service subsystems – background writer and checkpointer. Main aims of these subsystems is to clean dirty pages from shared buffers to a persistent storage. When data being read from disks into shared buffers clients may modify it and changes not written to the disks immediately. This is done by the background writer and checkpointer processes. There are a few differences I would like to point out here. The main aim of checkpointer is to periodically flush all dirty buffers and create checkpoint records in write-ahead log which is used for recovery purposes. Background writer is working permanently and cleans out dirty pages to disks, thus it reduces amount of work for checkpointer and maintains appropriate amount of clean pages that may be required for backend processes that handle user queries.
Thus by using pg_stat_bgwriter it is possible to understand whether bgwriter and checkpointer configured correctly. Here are a few points to consider: - quality of checkpoints;
- bgwriter settings.
Quality of checkpoints. As mentioned above, checkpoints sync data between dirty pages to persistent storage and create a special record in the WAL when flush is finished. There are two types of checkpoints (in fact, there are more than two but others are less relevant to this discussion): xlog checkpoints and timeout checkpoints.
In case of xlog, postgres collects a certain amount of WAL and forces to do a checkpoint. In case of timeout, postgres doesn’t have a lot of writing activity for triggering xlog checkpoint so it runs checkpoint after timeout. Checkpoints by timeout are preferable to xlog ones. The main reason is, if postgres collected a large amount of WAL and has to start xlog checkpoint, it needs to write a huge amount of dirty data. This means that the system is under stress during checkpoint and user queries may suffer as a result. The situation is becoming more complex when checkpoint is done by xlog and the next checkpoint starts immediately afterwards, thus they are running one after another and postgres writing changes as they come up, since if storage is overutilized it becomes a bigger issue.
In the case of checkpoint by timeout the amount of changes to write is evenly spread through timeout and storage doesn’t need to endure high amount of data from postgres.
To summarize, you should avoid checkpoints by xlog.
Settings that configure checkpoint behavior are specified in postgresql.conf, but they have one disadvantage – by default they aren’t designed for load-intensive workload, especially write load when postgres serves multiple CRUD operations. In this case the pg_stat_bgwriter helps to tune checkpoints’ settings in a better way. There are two columns: checkpoints_timed and checkpoints_req that show number of checkpoints occurred since last reset of stats. General rule is very simple – checkpoints_timed value should be much higher than checkpoints_req. It’s desirable when the last one (checkpoints_req) is near zero. It may be achieved by increasing max_wal_size (or checkpoint_segments) and checkpoint_timeout. Good starting point is to set max_wal_size to 10GB and checkpoint_timeout = 30min. Also, checkpoint_completion_target should be configured in a way that will enable spread of execution of checkpoints to time that is the closest to timeout or to size of collected WAL. A good starting point for this is 0.9. Thus, with this settings checkpoint will occur when postgres will collect 10GB of WAL, or after 30 minutes from last checkpoint. The already running checkpoint’s execution will spread over 27 minutes or until postgres again collects 9GB of WAL.
You may ask, what happens, when postgres needs to start a new checkpoint, when previous has not finished yet. In this case checkpointer begins sync buffers ignoring the checkpoint_completion_target with a maximum possible speed and starts next checkpoint when previous is finished. This is the worst case scenario and it should be avoided.
Bgwriter settings. pg_stat_bgwriter helps to estimate bgwriter effectiveness. Bgwriter is a background process that satisfies backends when it needs clean buffers in shared buffers area. Since the moment postgres was started, bgwriter has been working continuously and making tiny delays between processing buffers.
Delay means that sometimes bgwriter stops and if backends still require clean buffers, it has to clean buffers by itself. In general, it’s an unwanted behaviour since backends normally do bgwriter’s work. It also can be configured through postgresql.conf. Here is how – there are three settings that need to be adjusted:
bgwriter_delay – size of sleep delay when number of processed buffers exceeded.
bgwriter_lru_maxpages – number of processed buffers after bgwriter delays.
bgwriter_lru_multiplier – multiplier used by bgwriter to calculate how many buffers need to be cleaned out in the next round.
These settings used to make bgwriter more or less aggressive – lower values of maxpages and multiplier will make bgwriter lazier, and higher maxpages and multiplier with low delays will make bgwriter more diligent. In my experience you should aim to twist maxpages and multiplier to the maximum and reduce delay to the minimum – I have never seen that bgwriter was the source of problems with overutilized disks.
Now back to pg_stat_bgwriter, using its stats we can understand some moments related to bgwriter.- maxwritten_clean shows how many times bgwriter stopped because maxpages was exceeded. When you see high values there, you should increase bgwriter_lru_maxpages.
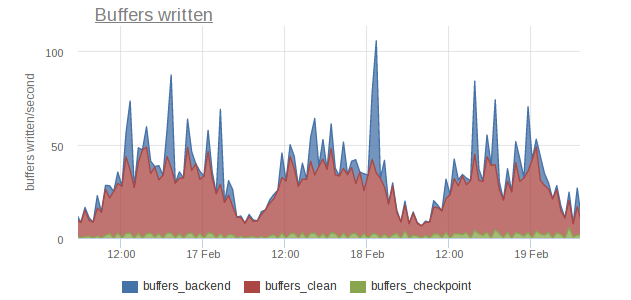
- buffers_clean and buffers_backend show number of buffers cleaned by bgwriter and postgres’ backends respectively – buffers_clean should be greater than buffers_backend. Otherwise, you should increase bgwriter_lru_multiplier and decrease bgwriter_delay. Note, it also may be a sign that you have insufficient shared buffers and hot part of your data don’t fit into shared buffers and forced to travel between RAM and disks.
- buffers_backend_fsync shows if backends are forced to make its own fsync requests to synchronize buffers with storage. Any values above zero point to problems with storage when fsync queue is completely filled. The newer versions of postgres addressed these issues and I haven’t seen non-zero values now for a long time.
After changing settings, I recommend resetting pg_stat_bgwriter stats with pg_stat_reset_shared(‘bgwriter’) function and re-check stats the next day.
To finalize I want to show you an example from pg_stat_bgwriter monitoring.
Here’s a observed host has intensive read workload during 3 days and aggressive bgwriter settings helps minimizing buffers cleaned out by backends.
Hope you enjoyed this post and will be on a lookout for my next one in these series.